绪论
在前些阵子的《ThreadLocal与ScopedValue》文章中,已经详细地描述了ThreadLocal与ScopedValue的作用。不同的多线程应用环境造就了不一样的两个本地线程缓存方案,实际项目开发中仍然是与多线程环境相互结合才能发挥它们最大的作用。
Java的并发编程是深奥而巧妙的,结构化并发和编排并发都属于并发编程的任何一个领域中的模型与技术。结构化并发主要关注如何更安全、更清晰地组织和管理并发的活动,比如线程或任务,使得它们的生命周期更易于理解和控制。编排并发主要关注如何更方便地描述和管理并发操作的顺序和依赖性。本期主要介绍编排并发以及与之相关的响应式编程初步内容。
理论认知
编排并发
并发编程的一个主要挑战是处理操作之间的依赖性,特别是在有多个异步操作需要以特定顺序执行时。编排并发的出现就是为了解决这个问题,提供一种方式来描述和控制并发操作的顺序和依赖性。在Java中CompletableFuture允许开发者以声明性的方式描述操作的顺序和依赖性,例如"当所有操作完成时进行..."或"当任何操作完成时进行..."。这种方式使得异步操作的编排变得更加直观和易于管理。
结构化并发
一个编排并发就写的要吐了,所以有关结构化并发的内容我会放到后面几期再讲
在传统的并发模型中,启动新的线程、任务或协程后,这些并发实体可能会无限期地运行,除非显示地停止它们。这可能导致程序难以理解和控制,也可能产生一些诸如资源泄露、难以捕获的错误等问题。结构化并发的出现,就是为了让并发编程更安全、更简洁,提供更强的错误处理,以及防止资源泄露。结构化并发通过强制并发操作具有明确的生命周期,并且这些生命周期嵌套在彼此之中,从而使并发操作的管理更具结构化。
问题背景
以CompletableFuture为主,围绕I/O密集型(I/O Bound)应用展开,最典型的案例便是外卖平台。外卖平台是一个非常经典的B2C中包含了C2C商业模式的应用。外卖平台每天都需要承担着为数以万计的商户、配送员、顾客提供实时消息的服务,这些服务随着订单量的不断上升让系统面临着巨大的压力。
作为外卖链路的核心环节,外卖APP商家端提供了商家接单、配送等一系列核心功能,业务对系统吞吐量的要求也越来越高。而商家端的API服务是流量入口,所有商家端流量都会由其调度、聚合,对外面向商家提供功能接口,对内调度各个下游服务获取数据进行聚合。在当前日订单规模达到千万级的情况下,使用同步加载方式的弊端逐渐显现,开发者急需通过并行加载来缓解服务器的压力。
同步与异步模型
一个简单的案例就足以讲明白同步于异步的区别,DNA在进行半保留复制时需要先解旋才能合成碱基链,这是一个同步的过程,因为聚合酶永远需要等待解旋酶或拓扑异构酶完成解旋工作才能继续;mRNA的翻译过程可以有多个rRNA附着于碱基链上同时进行多个蛋白质的合成,这是一个异步过程,因为每个rRNA都不需要等待上一个rRNA完成合成再继续。
同步模型
从各个服务中获取数据最常见的是同步调用,以电商为例,如下面的时序图所示:
在同步调用的场景下,接口耗时长、性能差,在加上网络波动、CPU降频等不可控因素影响,接口响应时长T > T1+T2+T3+……+Tn,这时为了缩短接口的响应时间,一般会使用线程池的方式并行获取数据:
在这个示例中,用户可以同时请求多个商品的详情,这些请求可以由线程池中的不同线程同时处理。因此,用户不需要等待商品1的详情返回就可以请求商品2的详情。
并行任务虽然可以在处理大量并发请求的情况下提高一定的性能,但是多线程并发本身又会造成一定的系统资源浪费,使系统吞吐量容易达到瓶颈:
-
CPU资源大量浪费在阻塞等待上,导致CPU资源利用率低。在Java 8之前,异步操作通常通过回调的方式来实现,即将一个函数(或方法)作为参数传递给另一个函数(或方法),并在操作完成或数据可用时调用它。在Java 8及以后的版本中,引入了
CompletableFuture,这是一个实现了Future接口的类,可以用于表示异步计算的结果。与传统的Future不同,CompletableFuture提供了更丰富的 API 来处理异步操作,包括链式操作、组合操作、异常处理等。这在一定程度上解决了“回调地狱”的问题。Java 9又引入了响应式流(Reactive Streams API)规范,为异步、事件驱动的数据处理提供了一种标准的模型。这个模型中,数据的生产者和消费者之间建立了一种回压(back-pressure)机制,使得消费者可以控制数据的产生速度,以避免在处理大量数据时发生内存溢出。 -
为了增加并发度,会引入更多额外的线程池,随着CPU调度线程数的增加,会导致更严重的资源争用,宝贵的CPU资源被损耗在CPU上下文切换上,而且线程本身也会占用系统资源,且不能无限增加。从Java 19开始推出结构化并发模型开始,开发者能通过更简单的并发编程模型来组织、管理并发任务,从而从一定程度上避免线程的重复创建和资源浪费。
异步模型
从回调到CompletableFuture,再到响应式流,这是Java在异步编程模型上的一种进化。每一种模型都在尽量减少阻塞,提高程序的响应性,同时也在尽量提高代码的可读性和可维护性。在Java 8以前主要通过以下两种异步模型来减少线程池的调度开销和阻塞时间:
-
通过RPC NIO异步调用的方式可以降低线程数,从而降低调度(上下文切换)开销。
-
通过引入CompletableFuture对业务流程进行并发编排,降低依赖之间的阻塞。
随着Java版本不断地迭代与更新,在Java 9中又引入了新的异步编程模型:
-
响应式流,这种模型为处理数据流提供了一套标准,特别适用于处理大量的数据流或者处理需要长时间等待的任务。
我们可以通过如下的表格更直观地看出各个异步模型之间的优胜劣汰:
| Future | CompletableFuture | Reactive Stream | RxJava | Reactor | |
|---|---|---|---|---|---|
| Composable(自由组合) | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
| Asynchronous(异步非阻塞) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Operator fusion(操作融合) | ❌ | ❌ | ❌ | ✔️ | ✔️ |
| Lazy(延迟执行) | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| Backpressure(反压机制) | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| Functional(函数式编程) | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
-
自由组合:可以将多个依赖操作通过不同的方式进行编排,例如
CompletableFuture提供thenCompose()、thenCombine()等各种then开头的方法,这些方法就是对“可组合”特性的支持。我们不妨参考JavaScript ES6中的Promise结构通过对后续操作进行then()或catch()的组合,以实现异步操作(Java 8发布于2014年,ES6发布于2015年)。 -
异步非阻塞:异步是指一个操作启动后,不必等待这个操作完成就可以进行其他操作。非阻塞是指在请求(例如 I/O 请求)不能立即得到满足时,不会挂起执行线程,而是允许执行线程继续执行其他任务。异步非阻塞模型能够更有效地利用系统资源,提高系统的并发性和吞吐量。
-
操作融合:将多个操作合并成一个操作以提高处理效率。这种方式可以减少不必要的中间结果的创建,节省内存,并可以减少任务调度的开销,提高总体的处理性能。这在响应式流中更为常见,类比到stream流操作可以更直观地理解这个概念
list.stream().map().filter().toList()。 -
延迟执行:绝大部分延迟执行方法的核心理念是使用函数式编程,在方法的最后通过调用
accept()等方法来执行定义好的操作。在函数式编程中,延迟执行是一种常见的模式。这种模式使得计算可以被推迟到需要结果的时候才执行,通常这是通过返回函数(或者称为"懒加载"的函数)来实现的。当这个返回的函数被调用时,原本需要立即执行的计算就会发生。许多非函数式的编程语言和环境也提供了一些实现延迟执行的机制,比如在 Java 中的 CompletableFuture,Reactor只有当有订阅者订阅时才会触发操作,JavaScript中的Promise只有当操作完成后才会执行then()。在后期的LazyOptional文章中我会重点介绍这种技术。 -
反压机制:反压机制是流处理系统中的一个关键概念,它允许接收方控制发送方的数据发送速率,防止接收方处理不过来而被压垮。在真正的反压机制中,接收方可以根据自己的处理能力,动态地调整发送方的生产速率,从而达到更好的流控效果。在响应式编程模型如Reactor或RxJava中,反压机制是内置的,并且能够更好地控制流量。在稍后的响应式流中会介绍到它。
-
函数式编程:部分人喜欢把函数式编程和匿名函数表达式这两个相关但不完全相同的概念混为一谈,我想,但凡编程素质较高的人也不会说出这些话。函数式编程是一种编程范式,而匿名函数表达式是这种范式中的一种技巧。匿名函数表达式广泛应用于函数式编程,但也可以在非函数式编程的语境中使用。
编排并发
我们普遍认同这样一个观点“在开发中只会使用lock()、unlock()、wait()、notify()来解决多线程问题的人基本都是基本功不扎实的人”,如果只知道如何使用这些同步机制,但不理解其背后的原理,那么就可能在面对复杂的并发问题时束手无策。编排并发不仅考察的是程序员在处理多线程或异步任务时,对任务之间依赖关系的理解、编程技巧更是对并发和异步概念的理解。
编排并发(CompletableFuture)始于Java 8,在Java 9得到进一步增强。CompletableFuture虽然实现了Future接口,但却是比FutureTask有着更优雅的代码结构、更低的多线程异步任务编排难度。
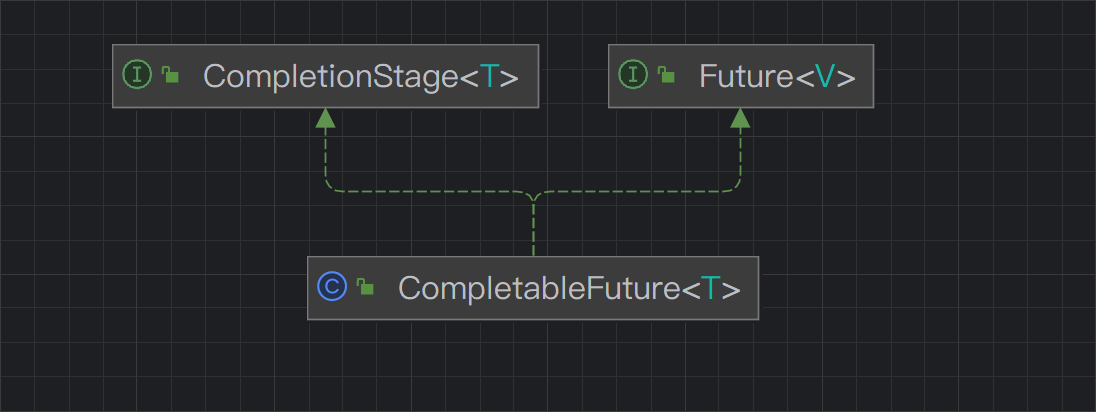
Future表示异步计算的结果,CompletionStage用于表示异步执行过程中的一个步骤(Stage),这个步骤可能是由另外一个CompletionStage触发的,随着当前步骤的完成,也可能会触发其他一系列CompletionStage的执行。从而我们可以根据实际业务对这些步骤进行多样化的编排组合,CompletionStage接口正是定义了这样的能力,我们可以通过其提供的thenAppy、thenCompose等函数式编程方法来组合编排这些步骤。
案例引入
我们可以把食堂就餐拆分成这样几步:
-
当你进入饭堂,首先你想的是我今天吃什么,选择合适的档口,比如有米饭、有面、有麻辣香锅。
-
当你选择了面档,下一步就是排队点餐告诉服务员今天你想点一碗青菜面。
-
服务员将任务通知给厨师开始为你准备青菜面。
-
等待期间你选择了一个不错的位置,并同时阅读Dioxide_CN的文章来耐心地等待青菜面。
-
厨师将准备好的青菜面交给服务员,服务员通知你前往档口取餐,这时你就可以开始享用青菜面了。
在Java 8以前我们会使用FutureTask来实现这个任务:
public static void main(String[] args) {
print("我 进入档口选择青菜面");
FutureTask<String> task1 = new FutureTask<>(() -> {
print("服务员 通知厨师制作青菜面");
sleep(200);
return "通知已下达";
});
new Thread(task1).start();
try {
task1.get(); // 等待 task1 完成
FutureTask<String> task2 = new FutureTask<>(() -> {
print("厨师 制作青菜面");
sleep(300);
return "青菜面";
});
new Thread(task2).start();
task2.get(); // 等待 task2 完成
FutureTask<String> task3 = new FutureTask<>(() -> {
print("服务员 通知顾客取餐");
sleep(100);
return "完成了通知和制作";
});
new Thread(task3).start();
print(task3.get() + ",我开始用餐"); // 等待 task3 完成,并打印结果
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
print("我 阅读Dioxide_CN的文章并同时等待用餐");
}

虽然FutureTask是可行的也输出了我们预期的结果,但是其代码的美观性、稳定性却不尽人意,也不利于后期开发者进行维护,同时又触发了令开发者极其厌恶的回调地狱问题。让我们再来看看使用CompletableFuture改进后的代码:
public static void main(String[] args) {
print("我 进入档口选择青菜面");
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
print("服务员 通知厨师制作青菜面");
sleep(200);
return "通知已下达";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
print("厨师 制作青菜面");
sleep(300);
return "青菜面";
}), (notification, result) -> {
print("服务员 通知顾客取餐");
sleep(100);
return "厨师" + notification + "并完成了" + result + "的制作";
});
print("我 阅读Dioxide_CN的文章并同时等待用餐");
print(cf1.join() + ",我开始用餐");
}

这是一段多么令人赏心悦目的实现方法,同时我们也能注意到CompletableFuture.supplyAsync()执行期间开辟的是一个ForkJoinPool线程池。
多元依赖
在实际开发场景中是不大可能出现上述案例中如此之简单的使用方法的,使用CompletableFuture是构建一个完整的依赖树的过程,一个CompletableFuture的完成会触发另外一个或一系列依赖它的CompletableFuture的执行,这就有点像链式反应。根据CompletableFuture依赖数量,可以将其分为以下几类:零依赖、一元依赖、二元依赖和多元依赖。
零依赖
零依赖关系是CompletableFuture最基础的依赖关系,这里直接给出案例,不需要做过多的介绍:
public class CompletableFutureExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int a = 2, b = 3;
// 异步任务1:获取两个数的和
CompletableFuture<Integer> futureSum = CompletableFuture.supplyAsync(() -> a + b);
// 异步任务2:获取两个数的乘积
CompletableFuture<Integer> futureProduct = CompletableFuture.supplyAsync(() -> a * b);
// 执行两个异步任务并输出结果
System.out.println("The sum is: " + futureSum.get()); // 阻塞,直到异步任务执行完成
System.out.println("The product is: " + futureProduct.get()); // 阻塞,直到异步任务执行完成
}
}
在这个案例中,创建了两个异步任务,分别计算两个数的和和两个数的乘积。因为这两个任务没有依赖关系,也就是零依赖关系,所以他们可以并行执行,我们通过调用 CompletableFuture.get() 方法来等待他们的执行结果。
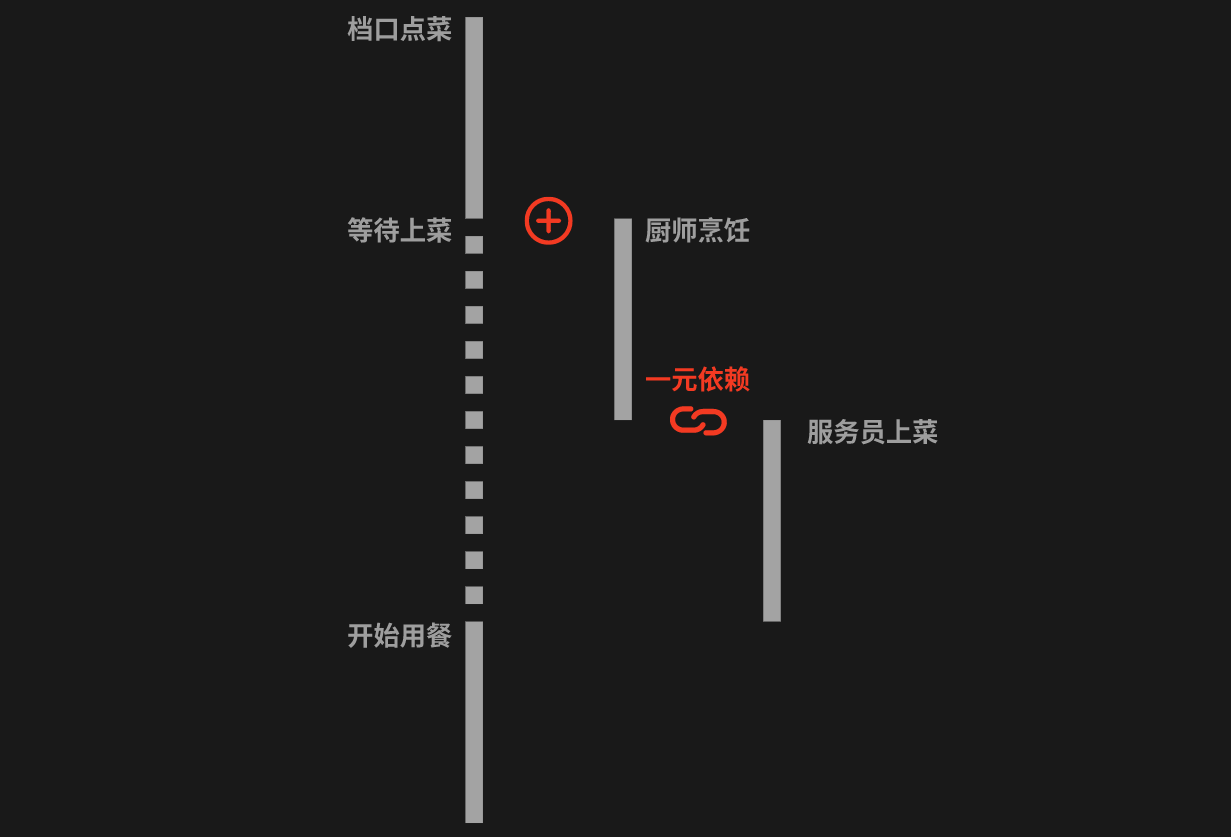
一元依赖
回到引入的案例来看一元依赖关系还是比较好理解的,这种对于单个CompletableFuture的依赖可以通过thenApply()、thenAccept()、thenCompose()等方法来实现。
二元依赖
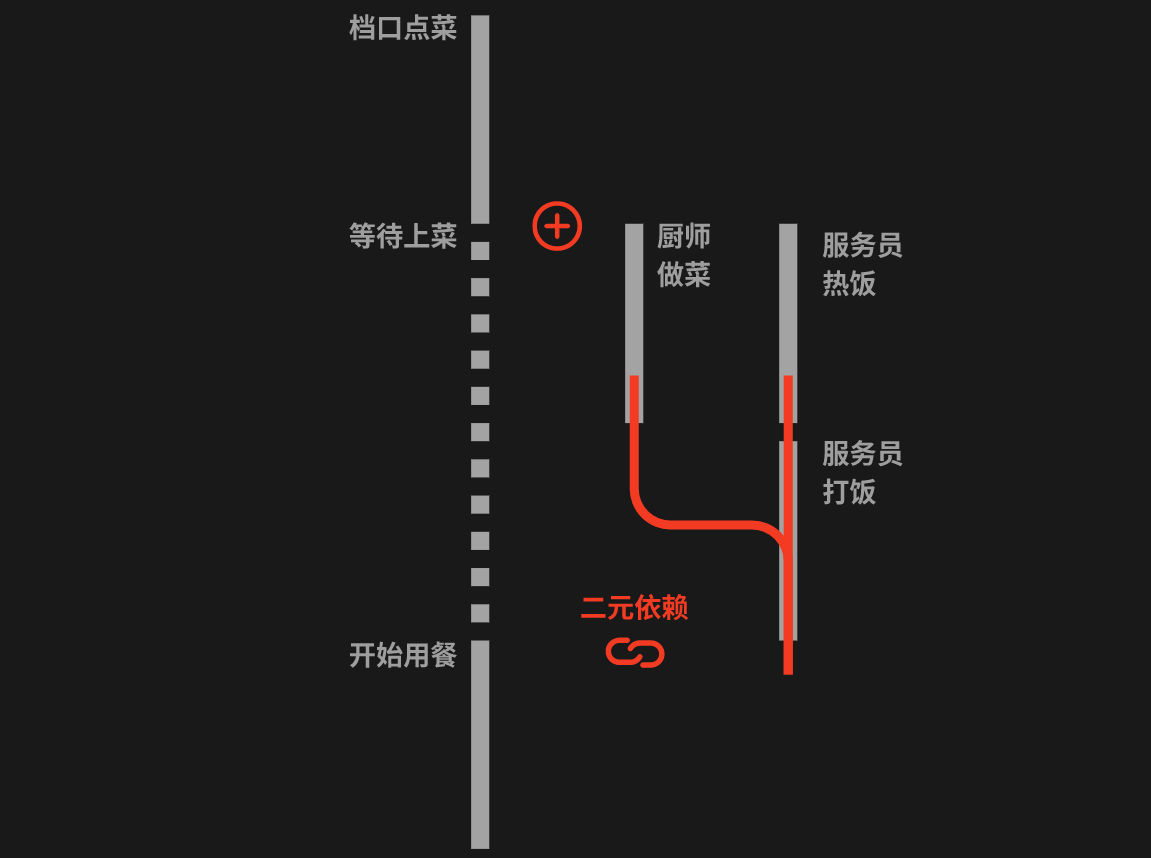
将方才的案例进行一次扩充,假设现在服务员同时需要负责热饭和打饭,那么最终顾客用餐就依赖于厨师上菜和服务员打饭这两件事,这就形成了一个二元依赖。二元依赖可以通过thenCombine()等回调来实现,具体的代码在案例引入中也有体现。
多元依赖
有了对一元依赖和二元依赖的理解基础,多元依赖则理解起来更加方便了。即一个任务依赖于它之前的多个任务的结果,多元依赖可以通过allOf或anyOf方法来实现,区别是当需要多个依赖全部完成时使用allOf(完全依赖),当多个依赖中的任意一个完成即可时使用anyOf(部分依赖)。
CompletableFuture<Void> cf6 = CompletableFuture.allOf(cf3, cf4, cf5);
CompletableFuture<String> result = cf6.thenApply(v -> {
// 这里的join并不会阻塞,因为传给thenApply的函数是在CF3、CF4、CF5全部完成时,才会执行 。
result3 = cf3.join();
result4 = cf4.join();
result5 = cf5.join();
// 根据result3、result4、result5组装最终result;
return "result";
});
更为复杂的依赖模型
在实际开发中我们并不会遇到一些单纯点到点的多元依赖模型,而是多种一元、二元、多元依赖形成的一个复杂的依赖模型。如下图所示。
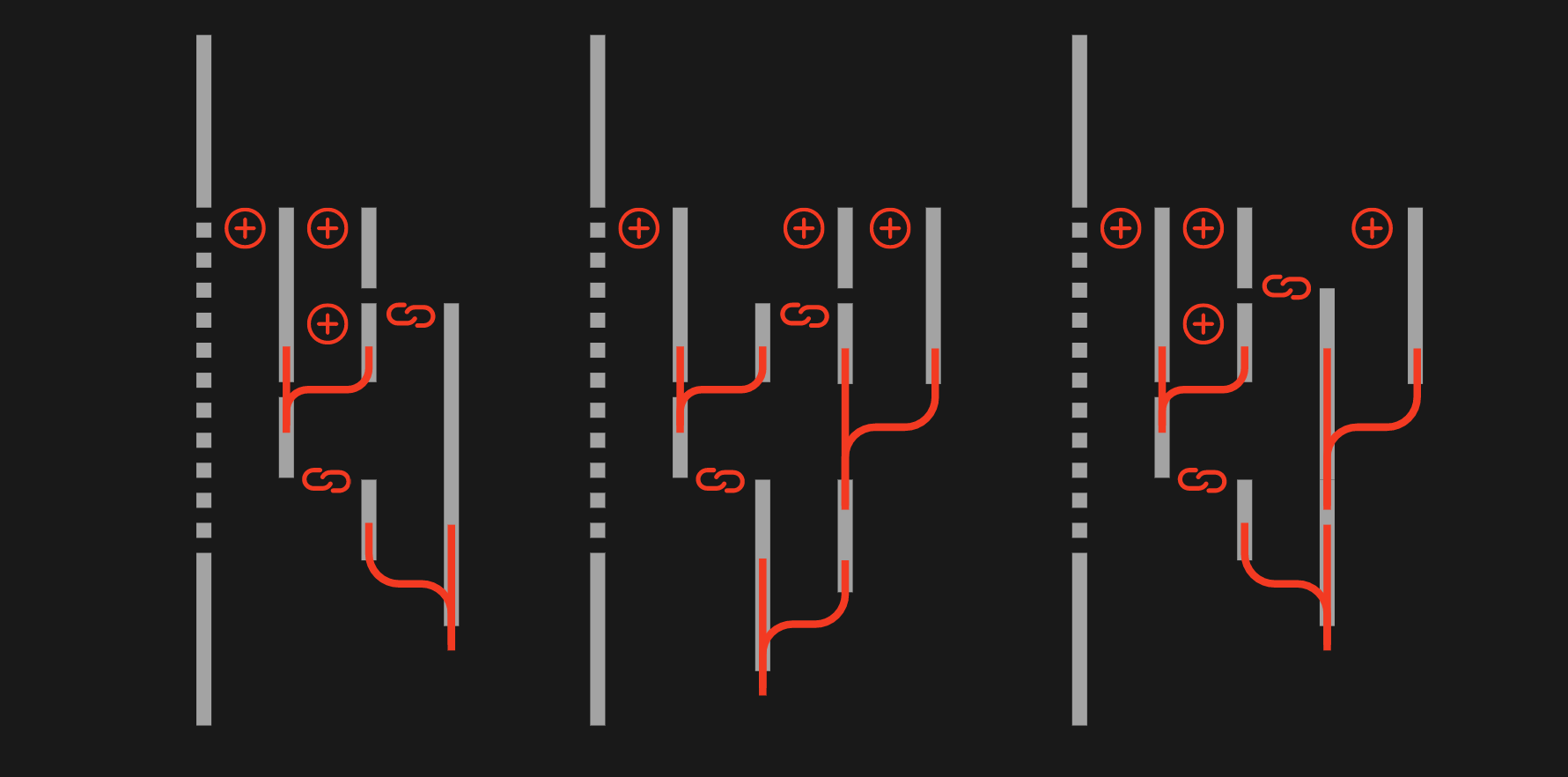
在处理这些更为复杂的依赖模型时,CompletableFuture相较于FutureTask能体现出绝对的优势,这也是为什么更多开发者更倾向于使用CompletableFuture来编排并发。
CompletableFuture底层原理
在CompletableFuture类中有两个被volatile修饰的变量Object result和Completion stack:
-
result:用于存储CompletableFuture的结果。它的类型是Object,因为CompletableFuture是一个泛型类,可以用于任何类型的计算结果。当CompletableFuture的计算完成时,结果就会被存储在这个变量中。 -
stack:用于存储所有的依赖任务,也是栈顶元素。当一个CompletableFuture对象完成时(即结果已经可用),所有依赖于这个CompletableFuture的任务(也就是那些通过thenApply、thenAccept、thenCompose等方法注册的任务)需要被执行,Completion stack就存储了这些待执行的任务。
Completion
Completion使用一种名为Treiber stack的数据结构来存储任务,这种结构类似于栈,遵循“先进后出(LIFO)”的规则。因此,最后注册的任务会被最先执行。这个结构可以在单线程环境下能保证更高效的任务管理。
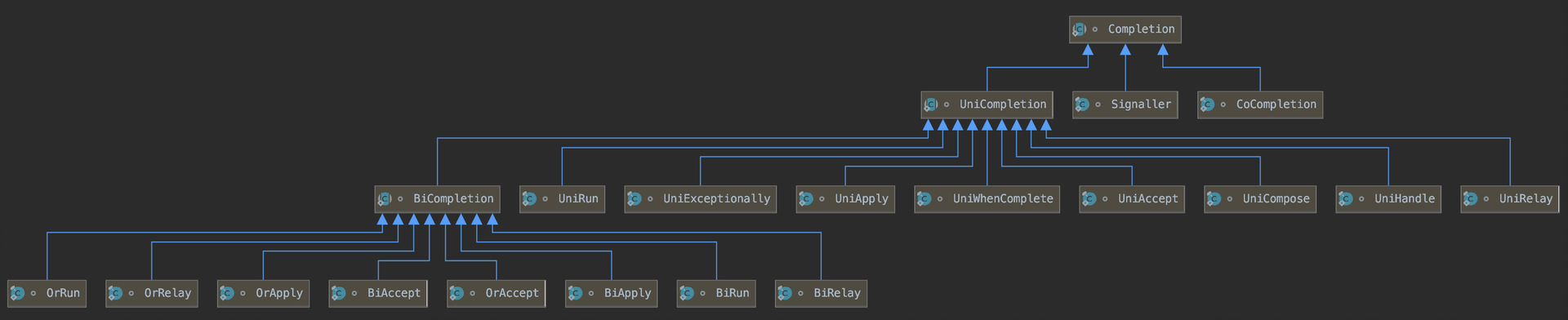
-
UniCompletion继承了Completion,是一元依赖的基类,例如thenApply的实现类UniApply就继承自UniCompletion。 -
BiCompletion继承了UniCompletion,是二元依赖的基类,同时也是多元依赖的基类。例如thenCombine的实现类BiRelay就继承自BiCompletion。
Treiber stack是一种无锁并发栈的数据结构,由R. Kent Treiber提出,可以在高并发环境下提供较好的性能。该Treiber stack借助VarHandle STACK通过一系列的CAS原子操作实现压栈和出栈的操作,这也是该数据结构能实现无锁并发栈的关键点之一。
VarHandle
如果读者还未了解过CAS原子操作可以阅读《CAS与自旋锁的实现原理》
VarHandle是Java 9引入的一个新的底层机制,主要目的是为了提供一种比sun.misc.Unsafe更安全、更易用的方式来支持各种复杂的原子性操作。VarHandle提供了一种标准化的机制来对各种数据类型进行访问,无论这些数据类型是静态的、实例的还是数组。它支持很多强大的操作,包括对单个变量的原子更新、对变量的有序或者易失的访问、对数组元素的有序或者易失的访问,以及对字段和数组元素的比较并设置(CAS操作)。
@SuppressWarnings("serial")
abstract static class Completion extends ForkJoinTask<Void>
implements Runnable, CompletableFuture.AsynchronousCompletionTask {
volatile CompletableFuture.Completion next; // Treiber stack link
/**
* Performs completion action if triggered, returning a
* dependent that may need propagation, if one exists.
*
* @param mode SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture<?> tryFire(int mode);
/** Returns true if possibly still triggerable. Used by cleanStack. */
abstract boolean isLive();
public final void run() { tryFire(ASYNC); }
public final boolean exec() { tryFire(ASYNC); return false; }
public final Void getRawResult() { return null; }
public final void setRawResult(Void v) {}
}
-
Completion Stack在
CompletableFuture中表现出了链表的特性,是一个以链表实现的栈,由Completion对象通过next字段链接而成。但是这并不冲突,它同时也符合了栈(Stack)的定义。当我们说Completion Stack是一个栈时,我们通常是指它的操作遵循LIFO原则。 -
无锁并发栈这个词则描述了Completion Stack的并发行为。无锁(Lock-Free)指的是即使在多线程环境下,也不需要使用传统的互斥锁来保护数据。而是通过原子操作来保证数据的一致性和线程的安全。这种方式可以减少线程阻塞,提高系统的并发性能。
在 CompletableFuture 中,VarHandle 用于实现对 Completion 链表的原子操作。Completion链表是 CompletableFuture 中用于存储依赖任务的数据结构,这些任务需要在 CompletableFuture 完成后被执行。VarHandle 提供了一种高效且线程安全的方式来操作这个链表。
通过使用 VarHandle,CompletableFuture 能够保证即使在并发环境中,依赖任务的添加、删除和执行也能正确无误地进行。而这一切都是通过原子操作以及对内存访问的精细控制来实现的,而无需依赖重量级的同步机制,如 synchronized 块或 Lock 对象。
处理依赖
无论是supplyAsync()也好还是runAsync()也好,他们最终都是通过指定的或内置的Executor来执行一个构建好的AsyncSupply或AsyncRun对象:
executor.execute(new AsyncSupply<U>(completableFuture, supplier)); // asyncSupplyStage 1778行
executor.execute(new AsyncRun(completableFuture, runnable)); // asyncRunStage 1815行
让我们将注意力放到这两个内部类上,它们都继承了ForkJoinTask<Void>并实现了Runnable和AsynchronousCompletionTask接口,重写的run()方法也极为相似。区别在于Runnable类型无法获取返回值因而在AsyncRun中使用的是completeNull()方法,而对于可以获取值的Supplier<>在AsyncSupply中使用的是completeValue()方法,并将结果通过CAS操作存储至VarHalde RESULT中。
这两个方法类似于观察者模式,在不同的线程中通过异步调用来实现通知观察者。继续向下走可以看到它们都调用了postComplete()方法:
final void postComplete() {
CompletableFuture<?> f = this; CompletableFuture.Completion h;
// 这个循环将会一直进行,直到f.stack为空,即没有更多的依赖需要处理
while ((h = f.stack) != null ||
(f != this && (h = (f = this).stack) != null)) {
CompletableFuture<?> d; CompletableFuture.Completion t;
// 将f.stack从h设为h.next,如果成功,那么h就会被移除出stack,同时t将会成为stack的新的栈顶元素
if (STACK.compareAndSet(f, h, t = h.next)) {
// 如果t不为null,则将当前的h压入this.stack,并继续下一次循环
if (t != null) {
if (f != this) {
pushStack(h);
continue;
}
NEXT.compareAndSet(h, t, null); // try to detach
}
// 执行h所代表的依赖动作,并将执行结果赋给d
f = (d = h.tryFire(NESTED)) == null ? this : d;
}
}
}
这个方法非常容易理解,通过一个while循环来处理当前CompletableFuture对象中所有依赖,保障当这个CompletableFuture完成后所有依赖它的回调函数都能被正确地执行。每次循环都会移除stack顶部的依赖,直到所有依赖都被处理完毕。这些操作都是通过VarHandle的原子操作来实现的。通过流程图可以更直观地分析这个流程:
绑定依赖
我们已经了解了CompletableFuture是如何处理依赖任务的了,接下来我们再来看添加依赖的操作是如何被执行的。在CompletableFuture中thenCombine()、thenCombineAsync()、thenCompose()、thenComposeAsync()都可以用来和前一个CompletableFuture绑定依赖关系,即便它们的工作方式和用途有所不同,这些不同之处我会在稍后讲到。现在我们先来分析这些方法的大致流程:
-
Compose调用的方法是
uniComposeStage并在内部调用一个传入UniCompose对象的unipush方法 -
Combine调用的方法是
biApplyStage并在内部调用一个传入BiApply对象的bipush方法
毋庸置疑,这两个类型都是在push阶段完成依赖绑定的,这个绑定的过程主要是构建出一种依赖关系,并将其压到Treiber stack栈中。现在分别跟踪这两类方法来看看具体是怎么实现的:
-
Compose,
thenCompose和thenComposeAsync方法的底层都是通过uniComposeStage方法来实现的,我们通过代码加注释的方法来解读它:private <V> CompletableFuture<V> uniComposeStage( Executor e, Function<? super T, ? extends CompletionStage<V>> f) { // 如果f为空,则抛出NPE if (f == null) throw new NullPointerException(); // 创建一个新的CompletableFuture实例d,它是一个未完成的CompletableFuture CompletableFuture<V> d = newIncompleteFuture(); Object r, s; Throwable x; // 检查当前CompletableFuture的结果result if ((r = result) == null) // 如果result为空,说明当前CompletableFuture还没有完成 // 那么创建一个新的UniCompose实例,并将它加入到依赖链中,同时等待当前CompletableFuture完成 unipush(new CompletableFuture.UniCompose<T,V>(e, d, this, f)); else { // 如果result不为空,说明当前CompletableFuture已经完成了,接下来就是执行f // 如果result是AltResult的实例,说明当前CompletableFuture完成的结果是一个异常 // 那么我们将这个异常设置到新的CompletableFuture的d中,然后返回d if (r instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)r).ex) != null) { d.result = encodeThrowable(x, r); return d; } r = null; // 将r重置为null并让GC来处理他 } // result不是AltResult的实例,说明当前CompletableFuture完成的结果是一个正常的值 // 接下来就是调用f来处理这个值。 try { // 如果传入的Executor e不为空,说明需要在指定的Executor中异步执行函数f // 通过创建一个新的UniCompose实例,并将其提交到Executor e执行 // 这里也是区分方法是否为Async的关键点 if (e != null) e.execute(new CompletableFuture.UniCompose<T,V>(null, d, this, f)); else { // 否则就是同步执行函数f @SuppressWarnings("unchecked") T t = (T) r; // 调用函数f,并获取返回的CompletionStage,然后将其转换为CompletableFuture CompletableFuture<V> g = f.apply(t).toCompletableFuture(); // 检查新的CompletableFuture的结果s // 如果s不为空,说明函数f返回的CompletableFuture已经完成了 // 那么就将这个结果设置到新的CompletableFuture的d中 if ((s = g.result) != null) d.result = encodeRelay(s); else // 如果s为空,说明函数f返回的CompletableFuture还没有完成 // 就需要创建一个新的UniRelay实例,并将它加入到依赖链中 // 等待函数f返回的CompletableFuture完成 g.unipush(new CompletableFuture.UniRelay<V,V>(d, g)); } } catch (Throwable ex) { d.result = encodeThrowable(ex); } } return d; }该方法的作用是实现
thenCompose和thenComposeAsync方法,即在当前CompletableFuture完成后,执行一个返回CompletionStage的函数f,并返回一个新的CompletableFuture,这个新的CompletableFuture的结果是函数f返回的CompletionStage的结果。显而易见的是
unipush这个方法负责处理新的Completion类型的实例并将其压入到Treiber stack栈内:final void unipush(CompletableFuture.Completion c) { // 检查传入的Completion对象c是否为null if (c != null) { // 循环调用tryPushStack(c)方法,尝试将c压入栈中直至成功 // 这是一个非常经典的循环自旋操作,可以类比到循环自旋锁方法 while (!tryPushStack(c)) { if (result != null) { // 将Completion c的next字段设为null // 这是为了断开c和其next之间的链接 // 避免后续的操作影响到c之外的Completion对象 NEXT.set(c, null); break; } } // 在压栈完成后若result不为空立即执行c if (result != null) c.tryFire(SYNC); } }整个压栈的过程并没有什么难点,就是将
thenCompose或thenComposeAsync中Function的apply结果作为一个新的Completion传递给unipush,unipush将这个Completion压入到stack栈顶,如果当前CompletionFuture已经产生结果了那么就立即通知这个栈顶元素执行操作,通过下面的流程图可以帮助读者更快速地回顾这些流程: -
Combine,
thenCombine和thenCombineAsync方法底层都是通过biApplyStage方法来实现的,虽然和Compose的有所不同但其理念基本都是相同的,我们仍然把重点落在绑定依赖的方法biApply()上:final <R,S> boolean biApply(Object r, Object s, BiFunction<? super R,? super S,? extends T> f, CompletableFuture.BiApply<R,S,T> c) { Throwable x; // 首先检查结果是否已经存在。如果结果已经存在,那么就直接返回true // 因为不希望对已经完成的CompletableFuture重复操作 tryComplete: if (result == null) { // 对两个结果r和s进行检查。如果这两个结果中的任何一个是CompletableFuture.AltResult类型 // 那么就通过completeThrowable方法来将这个异常设置为最终结果,并跳过后续步骤 if (r instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)r).ex) != null) { completeThrowable(x, r); break tryComplete; } r = null; } if (s instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)s).ex) != null) { completeThrowable(x, s); break tryComplete; } s = null; } // 如果两个结果都没有问题,那么就尝试将它们应用到BiFunction f上 try { // 这里用到了claim方法,它会尝试将Completion的状态 // 从未决定 (NEW) 更改为已决定 (COMPLETING) if (c != null && !c.claim()) return false; // 如果更改失败,就直接返回false // 如果更改成功,就会尝试应用BiFunction // 并使用completeValue方法来完成CompletableFuture @SuppressWarnings("unchecked") R rr = (R) r; @SuppressWarnings("unchecked") S ss = (S) s; completeValue(f.apply(rr, ss)); } catch (Throwable ex) { completeThrowable(ex); } } return true; }biApply并不是显式地进行依赖绑定操作的,它并不涉及到无锁并发栈的操作,与Compose也存在一定的区别:-
uniComposeStage是用于thenCompose或thenComposeAsync操作的,这些操作在一个CompletableFuture完成时就会执行。而biApply是用于thenCombine或thenCombineAsync操作的,这些操作在两个CompletableFuture的结果都完成时才会执行。 -
unipush方法主要是将一个Completion压入到stack中,如果CompletableFuture已经完成,那么就尝试执行这个Completion;而biApply方法是尝试将两个结果应用到一个BiFunction上,并完成CompletableFuture。这两个方法的执行策略和结果处理方式有所不同。 -
unipush方法处理的是一个Completion对象,而biApply方法处理的是两个结果和一个BiFunction。
通过下面的流程图可以更直观的感受到Combine与Compose的区别:
-
我们回过来再看看Combine和Compose这两类方法的区别:
-
thenCompose方法用于处理嵌套的CompletableFuture。它接受一个函数作为参数,这个函数的输入是前一个CompletableFuture的结果,输出是一个新的CompletableFuture。thenCompose会等待外层CompletableFuture和内层CompletableFuture都完成后才算完成。CompletableFuture.supplyAsync(() -> "Hello") .thenCompose(s -> CompletableFuture.supplyAsync(() -> s + " World")) .thenAccept(System.out::println); // "Hello World" -
thenCombine方法用于合并两个独立的CompletableFuture的结果。它接受两个参数,一个是另一个CompletableFuture,另一个是一个函数,这个函数会接受这两个CompletableFuture的结果作为输入,然后返回最终的结果。CompletableFuture.supplyAsync(() -> "Hello") .thenCombine(CompletableFuture.supplyAsync(() -> " World"), (s1, s2) -> s1 + s2) .thenAccept(System.out::println); // "Hello World"
超时与阻塞
通过大量的篇幅来介绍CompletableFuture,我们已经理解了CF的多元依赖与编排并发、如何处理依赖CF、如何绑定依赖关系。除了异常处理、延迟执行,我们还剩下最后的关于超时处理和线程阻塞的内容,异常处理和延迟执行的使用方法和底层实现并不复杂,所以这里只选择对超时与阻塞进行进一步的分析。
超时
超时处理是CompletableFuture在Java 9中添加的,包括orTimeout和completeOnTimeout这两个方法:
-
CompletableFuture<T> orTimeout(long timeout, TimeUnit unit):如果原始CompletableFuture在超时时间内完成,那么返回的CompletableFuture的结果就是原始的结果。如果原始的CompletableFuture在超时时间内没有完成,那么返回的CompletableFuture将以TimeoutException异常完成。 -
CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit):该方法返回一个新的CompletableFuture,如果原始的CompletableFuture在指定的超时时间内完成,那么返回的CompletableFuture的结果就是原始的结果。如果原始的CompletableFuture在超时时间内没有完成,那么返回的CompletableFuture将以给定的值value完成。
第二方法的处理更为优雅,我们可以将其对比到Optional.orElse方法上。这两个方法都会返回一个新的CompletableFuture,且不会修改原始的CompletableFuture。这一点与CompletableFuture的其他方法一致,确保了CompletableFuture的不变性。
但是这些超时方法并不会停止原始CompletableFuture的继续执行。如果任务没有被正确处理中断,那么可能会在超时后继续执行。因此,需要确保任务代码可以正确响应中断,做好灾容处理,以便在超时后立即停止执行。
在超时处理上,读者可以考虑以下问题:
-
Q:如果不设置超时时间或超时处理策略,对并发程序会造成什么危害?
A:这个问题应当从同步和异步两个角度出发进行考虑:-
同步任务:对于同步任务,如果一个操作由于各种原因(如网络波动、死锁等)而不能在预期的时间内完成,将阻塞主线程,影响后续任务的执行。这可能会导致程序挂起,无法处理新的请求。
-
异步任务:对于异步任务,如果一个操作由于各种原因(如无限循环,资源竞争等)长时间无法完成,那么这个异步任务可能会长时间占用线程资源,导致线程池中的线程不足,影响其他任务的执行。此外,由于
CompletableFuture的结果通常用于触发其他的计算或操作,如果一个CompletableFuture没有在预期时间内完成,可能会导致整个计算流程的延迟或挂起。
-
-
Q:在Java9以前既然没有超时的相关代码那么可以怎么实现这些方法?
A:即便在Java 9以前CompletableFuture没有提供超时策略,但依然可以使用曲线救国的策略来实现它们:-
ScheduledExecutorService:使用
ScheduledExecutorService来在特定的延迟后完成一个CompletableFuture。你可以使用CompletableFuture的complete方法来在超时后设置一个默认的结果或异常。这种方式的缺点是,超时并不会中断原来的任务,如果任务没有正确处理中断,那么可能会在超时后继续执行。public class CompletableFutureWithTimeout { public static void main(String[] args) throws ExecutionException, InterruptedException { // 创建一个用于执行超时任务的ScheduledExecutorService ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); // 创建一个将被执行的CompletableFuture CompletableFuture<String> completableFuture = new CompletableFuture<>(); // 创建一个Runnable任务,在该任务中超时后完成CompletableFuture Runnable timeoutTask = () -> { completableFuture.completeExceptionally(new TimeoutException("Timeout after 5 seconds")); }; // 在5秒后执行超时任务 ScheduledFuture<?> timeoutFuture = scheduler.schedule(timeoutTask, 5, TimeUnit.SECONDS); // 对CompletableFuture的完成进行监控,如果CompletableFuture在超时前完成,则取消超时任务 completableFuture.whenComplete((result, ex) -> { if (ex == null) { timeoutFuture.cancel(false); } else { System.out.println("CompletableFuture completed exceptionally: " + ex.getMessage()); } }); // 模拟的长时间任务,假设需要10秒才能完成 CompletableFuture.runAsync(() -> { try { Thread.sleep(10000); } catch (InterruptedException ignored) {} completableFuture.complete("Task completed"); }); // 获取CompletableFuture的结果,如果CompletableFuture已经超时,那么get方法将抛出ExecutionException try { String result = completableFuture.get(); System.out.println("Result: " + result); } catch (ExecutionException e) { if (e.getCause() instanceof TimeoutException) { System.out.println("Task timed out"); } } // 最后,记得关闭ScheduledExecutorService scheduler.shutdown(); } } -
Future.get:对于
Future,可以使用get(long timeout, TimeUnit unit)方法来等待Future在指定的超时时间内完成。如果超过了这个时间,get方法会抛出一个TimeoutException。然而,这个方法只能用于阻塞式的等待,不适用于异步编程模型。
-
阻塞
通常使用同步阻塞的方式来处理任务的情况有这么几种:
-
处理的数据量较小,任务的执行时间较短
-
各个任务之间有严格的执行顺序,需要更方便的管理和控制
-
项目的需求和业务逻辑较为简单
-
数据交互频次低,IO不密集的应用
-
系统资源(如CPU、内存)紧张,使用并发会耗尽系统资源
而在异步并发的环境中,我们需要合理地安排线程资源,而合理安排的前提条件是清晰地认识到任务分配到了哪个线程中:
-
如果注册时被依赖的操作已经执行完成,则由前置依赖任务所在的线程执行
-
如果注册时被依赖的操作还未执行完,则由回调任务的线程执行
在前面解决依赖与绑定依赖的解析中提及了同类型的Async方法变种,这些方法中都有一个需要传入一个Executor executor的重载方法。在开发中更推荐使用需要传入线程池的异步方法,当不传递线程池时,会使用ForkJoinPool中的公共线程池CommonPool,因此所有的异步回调任务都会被挂载到这个公共线程池中,,核心与非核心业务都竞争同一个池中的线程,很容易造成系统瓶颈。手动传递线程池参数可以更方便的调节参数,并且可以给不同的业务分配不同的线程池,以求资源隔离,减少不同业务之间的相互干扰。
在# CompletableFuture原理与实践-外卖商家端API的异步化一文中提到了线程池循环引用会导致死锁的问题,其举例的代码如下:
public Object doGet() {
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
//do sth
return CompletableFuture.supplyAsync(() -> {
System.out.println("child");
return "child";
}, threadPool1).join();//子任务
}, threadPool1);
return cf1.join();
}
发生死锁的原因是主任务和子任务共用一个线程池,且主任务依赖子任务的结果。当并发的主任务数超过线程池的大小时,每个主任务都会阻塞等待其子任务的结果,而子任务无法得到执行因为线程池中所有的线程都被阻塞的主任务占据,形成了死锁。同样的,不仅仅是父子关系的任务会发生死锁,只要两个以上并形成依赖关系的任务同时使用一个线程池时都有可能会发生死锁:
public Object doGet() {
ExecutorService threadPool = Executors.newFixedThreadPool(1);
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "cf1";
}, threadPool);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {
try {
return cf1.get(); // 这里等待cf1的结果
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return null;
}, threadPool); // cf1和cf2在同一个线程池
return cf2.join();
}
CompletableFuture在如今的并发编程中承担着至关重要的角色。作为Java 8中引入的一种强大的并发编程工具,它带来了一种全新的编程范式——基于回调和链式调用的异步编程模式。在面对复杂的并发场景时,如网络请求、数据库访问等IO密集型任务,CompletableFuture以其强大的功能和灵活的API,让开发者可以更容易地构建高效、稳健的并发应用,这在很大程度上推动了Java在服务端编程、大数据处理等领域的广泛应用,在当今的并发编程中无疑占据了核心地位。
FutureTask的剩余价值
FutureTask和CompletableFuture都是Java中的并发工具类,它们都实现了Future接口,可以用来表示一个异步计算的结果。尽管CompletableFuture提供了更丰富的功能和更好的编程模型,但FutureTask仍然有其存在的价值和适用场景。FutureTask和CompletableFuture各有优缺点,适用于不同的场合,使用哪个更适合应当取决于具体的需求和环境:
-
兼容性:
CompletableFuture是在Java 8中引入的,而FutureTask则是在Java 5中引入的。因此,对于一些老的Java代码和库,或者一些仍然需要支持Java 7及更早版本的项目,FutureTask是更好的选择。 -
简单性:虽然
CompletableFuture提供了更强大的功能,但这也使得它的使用和理解变得稍许复杂。对于一些简单的并发需求,使用FutureTask可能会更简单和直观。 -
cancel取消任务:
FutureTask提供了一个cancel方法,可以用来取消任务的执行。虽然CompletableFuture也提供了类似的功能,但FutureTask的取消功能更直接和简单。 -
RunnableFuture:
FutureTask实现了RunnableFuture接口,这使得它可以直接被线程执行,而CompletableFuture则没有这个功能。这使得FutureTask在某些场合下可以提供更好的性能和灵活性。
响应式流
本节不会过多地深入探讨响应式流的底层实现或应用,只是做一些基本概念的介绍,后面会单独开一期Spring WebFlux来作进一步介绍和源码分析。
案例引入
Reactive Streams是对异步流式编程的一种实现。响应式流基于异步发布和订阅模型,具有非阻塞“背压”数据处理的特点。响应式流是一套更为强大的异步变成规范,基于这种规范衍生出了RxJava以及Reactor这些强大的响应式库。这些库提供了更高级别的API,使得开发者可以更方便地处理流式数据,包括创建、转换、组合以及消费流。
俗话说“民以食为天”,这次依旧以排队就餐为例,使用Reactor来演示一个简单的响应式流程序。
public static void main(String[] args) {
print("我 进入档口选择青菜面");
Mono<String> notice = Mono.fromCallable(() -> {
print("服务员 通知厨师制作青菜面");
sleep(200);
return "通知已下达";
}).subscribeOn(Schedulers.boundedElastic());
Mono<String> cook = Mono.fromCallable(() -> {
print("厨师 制作青菜面");
sleep(300);
return "青菜面";
}).subscribeOn(Schedulers.boundedElastic());
print("我 阅读Dioxide_CN的文章并同时等待用餐");
Mono.zip(notice, cook)
.map(tuple -> {
print("服务员 通知顾客取餐");
sleep(100);
return "厨师" + tuple.getT1() + "并完成了" + tuple.getT2() + "的制作";
})
.doOnNext(result -> {
print(result + ",我开始用餐");
})
.block();
}

虽然这段响应式流也实现了我们的需求,但是可以发现它的运行耗时永远比CompletableFuture要多出100毫秒左右。这个现象主要是由于操作系统的线程调度策略或JVM的工作负载导致的。
响应式规范
Reactive Streams是一个由Netflix、Pivotal(现在的VMware)、Lightbend(之前的Typesafe)和其他几家公司联合提出的响应式流规范,它并不是由Java语言或者Oracle公司提出的。这个规范定义了一组接口(
Publisher、Subscriber、Subscription和Processor),以及一组与之相关的行为和协议,以支持异步的、背压(backpressure)感知的流处理。
Java 9引入的java.util.concurrent.Flow类及其四个嵌套的接口都是对Reactive Streams规范的实现。它的目标是提供一种标准的、低级的响应式编程API,以便各种基于Java的库和框架可以在这个API之上构建更高级的API和功能。
此外Reactor、RxJava、Akka Streams等框架也是基于Reactive Streams规范实现的。它们在规范的基础上提供了大量的操作符和便捷的API,以支持各种复杂的流处理和转换。所以我们需要明确,这些框架都是基于Reactive Streams规范而非Java 9的Flow API开发的,所以它们并不依赖于Java 9,可以在更早的Java版本上运行。如,Reactor 3和RxJava 2都可以在Java 8上运行。
这套规范中的接口我们可以在reactive-streams依赖或Java 9的Flow类中找到,在本章中我们主要以Reactor框架进行介绍。
implementation 'org.reactivestreams:reactive-streams:1.0.4'
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.4</version>
</dependency>
发布订阅模式
发布订阅模式(Publish-Subscribe Pattern)是一种消息传递或事件系统的模式,在此模式中,发送消息的一方(发布者)并不直接发送给特定的接收者(订阅者)。相反,发布的消息会被归类到某一类,而没有明确的接收者。订阅者能够表达对一个或多个类别的兴趣,只接收感兴趣的消息,发布者和订阅者通常没有直接的关系(低耦合)。
发布订阅模式是实现响应式流的核心要点,这也是“响应”一词所表达的含义。我们可以通过一个简单的示例模型来了解它:
interface Subscriber { // 订阅者
void update(String message);
}
class Publisher { // 发布者
private final List<Subscriber> subscribers = new ArrayList<>();
void subscribe(Subscriber subscriber) {
subscribers.add(subscriber);
}
void publish(String message) {
subscribers.forEach(subscriber -> subscriber.update(message));
}
}
class ConcreteSubscriber implements Subscriber {
private final String name;
ConcreteSubscriber(String name) {
this.name = name;
}
@Override
public void update(String message) {
System.out.println(name + " received: " + message);
}
}
public class Main {
public static void main(String[] args) {
Publisher publisher = new Publisher();
Subscriber bob = new ConcreteSubscriber("Bob");
Subscriber alice = new ConcreteSubscriber("Alice");
publisher.subscribe(bob);
publisher.subscribe(alice);
publisher.publish("Hello, World!");
}
}
其对应的时序图如下:
在响应式编程中,这种模式被扩展和改进,以支持数据流的异步处理和背压(backpressure)管理。在Reactive Streams规范和基于该规范的响应式框架(如Reactor、RxJava等)中,Publisher(发布者)会发送数据流给Subscriber(订阅者),而Subscriber可以控制接收的数据流的速率。
在Java 9中,官方将这种响应式流的简易版封装到了java.util.concurrent这个JUC并发包中,可见响应式对并发编程的重要作用与价值。
数据背压
背压(Backpressure)是流控制机制的一种,是响应式系统处理数据流速度不匹配问题的一种方法。在响应式编程中,背压的概念非常重要。我们不妨考虑这样一个场景,当发布者(Producer)产生数据的速度快于订阅者(Subscriber)消费数据的速度时,就会出现问题。如果没有控制机制,订阅者可能会被大量积压的数据淹没(消息积压),这可能会导致订阅者的资源耗尽(例如内存溢出)或者性能下降。
背压机制就是为了解决这种情况的。在背压机制下,订阅者可以控制它接收数据的速率,从而确保它不会被积压的数据淹没。在响应式流规范(Reactive Streams)中,背压是通过Subscription接口实现的。订阅者可以通过Subscription.request(n)方法来告诉发布者,它现在可以处理n个元素。当订阅者准备好处理更多的元素时,它可以再次调用这个方法。另一方面,订阅者也可以通过Subscription.cancel()方法来告诉发布者,它不再需要数据,从而取消订阅。
我们仍然以食堂就餐为例,以Reactor的Flux为基本类实现一个背压。假设就餐顾客可以一次食用5盘番茄炒蛋,每次食用的速度为500毫秒/盘,但是餐厅后厨出餐番茄炒蛋的速度是200毫秒/盘。这是一个非常明显的发布者发消息的速度大于消费者消费消息的速度的案例,这就需要通过背压来控制:
public static void main(String[] args) {
Flux<String> foodFlux = Flux.interval(Duration.ofMillis(200)) // 每200毫秒端出一盘番茄炒蛋
.map(i -> "番茄炒蛋" + i);
// 使用BaseSubscriber实现背压控制
foodFlux.subscribe(new BaseSubscriber<>() {
int count = 0; // 记录食用的番茄炒蛋数量
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println("开始排队取餐");
request(1); // 一次只取一份番茄炒蛋
}
@Override
protected void hookOnNext(String food) {
System.out.println("选择: " + food);
count++;
try {
Thread.sleep(500); // 假设每次食用番茄炒蛋需要500毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("已食用: " + food);
if (count >= 5) { // 假设最多吃5份番茄炒蛋
cancel();
} else {
request(1); // 继续取下一份番茄炒蛋
}
}
@Override
protected void hookOnCancel() {
System.out.println("顾客已饱腹,结束就餐");
}
});
try {
Thread.sleep(5000); // 主线程等待5秒钟以便观察输出
} catch (InterruptedException e) {
e.printStackTrace();
}
}
如果读者使用过MQ消息队列(ActiveMQ、RabbitMQ、Kafka、RocketMQ、Pulsar等)会对这个过程非常熟悉,在许多情况下,响应式编程和消息队列系统在处理背压上的策略有很多相似之处。MQ在处理生产者和消费者之间的速率不匹配问题时,都使用了一种缓冲区的机制,也就是消息队列,来缓存生产者产生的数据,而消费者则按照自己的处理能力从队列中取出数据处理。
此外,这些系统通常还提供了更细粒度的流控制机制,例如批量获取消息、调整消费者的并发数等,以便更好地处理速率不匹配的问题。而在响应式编程中,类似的功能可以通过Reactor、RxJava等库中提供的操作符实现。
但是,即便他们很相似但在实现细节、使用场景、设计目标等方面还是存在很大的不同之处的,消息队列系统通常用于处理分布式系统中的异步消息传递问题,而响应式编程更多地是用于构建高效的、基于事件驱动的程序。
发布者
发布者(Publisher)是数据的生产者,在不同的框架中被设计为了不同的类名:
-
Observable(RxJava)/ Mono(Reactor):可以代表0个元素序列的发布者
-
Single(RxJava)/ Mono(Reactor):可以代表1个元素序列的发布者
-
Observable(RxJava)/ Flux(Reactor):可以代表0到N个元素序列的发布者
在操作这些序列时,可以使用各种操作符(map、filter、flatMap等)。这些异步、非阻塞的操作符可以对序列进行各种复杂的操作。以Reactor为例:
Flux<Integer> flux = Flux.range(0, 100) // 用Flux发布一个0到100的随机数
.map(i -> i * 2) // 对Flux内的元素扩大两倍处理
.subscribe(System.out::println); // 订阅给输出任务来打印结果
Mono.just("Hello, World!") // 用Mono发布一个字符串
.subscribe(System.out::println); // 订阅给输出任务来打印结果
订阅者
在响应式编程中,订阅者是数据流的消费者。订阅者通过订阅发布者(Publisher)来接收数据流,并对接收到的数据进行处理。订阅者需要实现Reactive Streams规范中定义的Subscriber接口,该接口包括四个方法:onSubscribe(Subscription)、onNext(T)、onError(Throwable)和onComplete(),这四个方法分别在订阅开始、接收到数据、出错和完成时被调用。
调度器
调度器(Scheduler)用于控制数据流的处理和发布在哪个线程上执行。在Reactor和RxJava这样的响应式编程库中,提供了多种调度器,例如用于并行处理的Schedulers.parallel()、用于单线程处理的Schedulers.single()等。通过使用不同的调度器,你可以将处理任务调度在不同的线程或线程池上,从而实现异步、并发或并行的处理。
例如,以下的代码创建了一个Flux,并指定在异步的线程上生成数据,在主线程上处理数据:
public class SchedulerExample {
public static void main(String[] args) {
Flux<Integer> flux = Flux.range(1, 5)
.publishOn(Schedulers.boundedElastic()) // 用于异步的调度器
.map(i -> {
System.out.println("发布 " + i + " 在 " + Thread.currentThread().getName());
return i * i;
})
.subscribeOn(Schedulers.parallel()) // 用于并行处理的调度器
.doOnNext(i -> System.out.println("处理 " + i + " 在 " + Thread.currentThread().getName()));
flux.subscribe();
}
}
在这个例子中,.publishOn(Schedulers.boundedElastic())将生成数据的任务调度到了一个用于异步处理的线程上,.subscribeOn(Schedulers.parallel())将处理数据的任务调度到了一个用于并行处理的线程上。
参考文献
[1] 长发 & 旭孟 & 向鹏. (2022.5). CompletableFuture原理与实践-外卖商家端API的异步化. Retrieved from https://tech.meituan.com/2022/05/12/principles-and-practices-of-completablefuture.html
[2] Grzegorz Piwowarek. (2019.7). CompletableFuture – The Difference Between thenApply/thenApplyAsync.Retrieved from https://4comprehension.com/completablefuture-the-difference-between-thenapply-thenapplyasync/
[3] Martin Buchholz & David Holmes. (2015.3). Rare lost unpark when very first LockSupport.park triggers class loading. Retrieved from https://bugs.openjdk.org/browse/JDK-8074773
[4] 方腾飞 & 魏鹏 & 程晓明. (2015). Java并发编程的艺术. 机械工业出版社. (Original work published 2015)
[5] Defog Tech. (2018.1). Introduction to CompletableFuture in Java 8. Retrieved from https://www.youtube.com/watch?v=ImtZgX1nmr8
[6] 知秋z. (2021.10). Java编程方法论-Reactor-Netty与Spring WebFlux解读 整体简介与导读. Retrieved from https://zhuanlan.zhihu.com/p/390603119
[7] Spring Official. (2023.5). Spring Framework WebFlux Overview. Retrieved from https://docs.spring.io/spring-framework/reference/web/webflux/new-framework.html