引言
截止2023年5月18日,Oracle、Azul等公司或是一些博客都未对JCTree、Tokens、Token、TokenKind等做出过详细的介绍和解释。因为它们属于javac编译器的内部实现细节,而非Java公开的API。以下的内容都是博主通过阅读源码和阅读零散的其他博客的文章总结的,如若读者感兴趣,最直接的途径可能就是阅读 javac 的源代码,或者查找一些关于 Java 编译器实现的教材或论文。您也可以在评论区为我指正或提供更详细的信息,这将使得这篇文章更加完善。
Java词法树(语法树)这种树形结构是Java源码的一种抽象表示,它以图形化的方式反映出代码的语法结构,从而帮助开发者更好地理解和解析程序的语义。
每个树节点代表源代码中的一个构造或表达式(声明、循环、条件判断等)。根据这些节点以及它们之间的关系,可以详细地解析出代码的执行逻辑。这对于程序的优化、重构、测试等许多领域都有着至关重要的影响。
Java词法树并不只是编译器的工具,它的用途远远超出了这个范围。在很多工具和技术中,如静态代码分析工具、代码格式化工具、重构工具等,都会使用到词法树。此外,通过对词法树的深入研究,可以对JDK实现自定义关键字,这对于定制化JDK开发创造了无限可能。
在这期文章中,我将深入探讨JDK17u中词法树的结构和用途,详细阐述如何通过词法树实现自定义关键字。深入理解和研究Java词法树,可以帮助开发者们提升编程技能,为开发者带来编程语言的全新理解。
JCTree
JCTree是Java编译器内部使用的一种数据结构,它位于com.sun.tools.javac.tree包中,用于表示Java程序的抽象语法树(Abstract Syntax Tree,AST)。JCTree在编译器源代码的语法分析阶段生成,用于表示和处理Java源代码的结构。JCTree包含了多种子类的抽象类,这些子类代表Java语法中的各种结构,重要的几个包括:
-
JCMethodDecl:代表方法声明
-
JCVariableDecl:代表变量声明
-
JCClassDecl:代表类声明
-
JCModifiers:代表访问标志
-
JCExpression:代表一个表达式
-
JCIf:代表if语句
-
JCBlock:代表语句块
-
JCReturn:代表return语句
每个JCTree的实例都代表源代码中的一个语法结构,在JDK17u的源码中JCTree包含了多达73个实例,JCTree中内部类之间的关系错综复杂,具体如下图(查看请下载原图):

抽象性质
JCTree是一个实现了Tree, Cloneable, DiagnosticPosition接口的抽象类:
public abstract class JCTree implements Tree, Cloneable, DiagnosticPosition
JCTree代表了Java编译器中的AST节点的一般概念。AST中的每一个节点都可以看作是一个JCTree(如JCStatement),具体的节点类型(如方法声明、变量声明、if语句等)都有各自不同的属性和行为。因此,JCTree定义为抽象类,可以为各种具体的AST节点类型提供一个共享的接口,同时还能强制这些节点类型实现某些必要的方法。以内部抽象类JCStatement为例:
// 内部JCStatement抽象类继承JCTree实现StatementTree接口
public static abstract class JCStatement extends JCTree implements StatementTree {
// 重写JCTree中的setType方法
@Override
public JCStatement setType(Type type) {
super.setType(type);
return this;
}
// 重写JCTree中的setPos方法
@Override
public JCStatement setPos(int pos) {
super.setPos(pos);
return this;
}
}
JCStatement作为抽象类又可以被其他AST节点继承进一步实现更详细的AST节点,如JCVariableDecl、JCBlock、JCDoWhileLoop、JCWhileLoop、JCForLoop等。
这种设计模式被称为"访问者模式",它是处理AST这种复杂数据结构的常见方法。在这种模式中,抽象节点类(JCTree)和具体节点类(JCMethodDecl)分别代表"元素"和"具体元素",而访问者类则代表"访问者"。
pos变量
在JCTree中定义了一个pos变量public int pos;,该变量通常表示该语法结构在源代码文件中的字符偏移量(语法结构的位置信息)。
例如,假设我们有一个表示变量声明的JCTree节点(例如JCVariableDecl),那么pos可能会表示这个变量声明在源代码文件中的开始位置。这种位置信息对于许多编译器任务来说都非常重要,比如在报告错误或警告时,编译器需要知道问题出在源代码的哪个位置。同时,这种位置信息也可以被用于其他的代码处理工具,比如用于代码导航或者高亮显示特定代码片段。
需要注意的是,pos变量的具体含义和使用方式可能会依赖于编译器的具体实现。在一些特殊情况下,它可能不是一个精确的字符偏移量,而是一个相对位置或者其他类型的位置标识。因此,在使用这个变量时,需要参考具体的编译器文档或者源码。
在com.sun.tools.javac.tree.TreeCopier类中,在M.at(t.pos)代码中就使用到了JCTree的pos变量。其中的M是一个com.sun.tools.javac.tree.TreeMaker对象,用于创建新的树节点。M.at(t.pos)则设置了新创建节点的位置为与原节点相同的位置,t.pos就是原节点在源代码中的位置。这在错误报告、代码生成等场景下非常有用,因为我们可以通过节点在源代码中的位置追踪到源代码的具体行数和字符位置。
@DefinedBy(Api.COMPILER_TREE)
public JCTree visitAnnotation(AnnotationTree node, P p) {
// 将AnnotationTree转换为JCAnnotation
JCAnnotation t = (JCAnnotation) node;
// 复制注解类型和注解参数,保存为局部变量
JCTree annotationType = copy(t.annotationType, p);
List<JCExpression> args = copy(t.args, p);
// 检查原始注解是类型注解还是普通注解
if (t.getKind() == Tree.Kind.TYPE_ANNOTATION) {
JCAnnotation newTA = M.at(t.pos).TypeAnnotation(annotationType, args);
newTA.attribute = t.attribute;
return newTA;
} else {
JCAnnotation newT = M.at(t.pos).Annotation(annotationType, args);
newT.attribute = t.attribute;
return newT;
}
}
With boot jdk
在上一期《JDK源码编译与版号控制》中在不同的操作系统中构建预编译环境都需要提供--with-boot-jdk选项,这个选项为JDK编译提供了一个所谓的“引导”JDK(boot jdk),也就是已经存在的、功能完整的JDK实例。这个引导JDK被用来启动编译过程,并编译新版本的JDK源代码。
JDK的源代码包括Java编译器(javac)的源代码,虽然javac的源代码中确实包含JCTree等类。但是,为了编译这些源代码,编译过程仍然需要一个已经存在的Java编译器来编译这些Java代码,这就是引导JDK的作用。
实际上,任何自我托管的编程语言(也就是用自己的语言编写的编译器)都需要一个这样的引导过程。在编译JDK的过程中,引导JDK首先会被用来编译javac的源代码,生成新的Java编译器。然后,这个新的编译器会再次被用来编译所有的JDK源代码,生成新版本的JDK。
在编译JDK时,即使源代码中包含JCTree等类,也需要引导JDK来启动编译过程。这也就意味着,为了构建编译环境,我们确实需要提供一个引导JDK。这也就能间接地证明boot JDK存在的必要性。
Tokens
与JCTree不同的是,com.sun.tools.javac.parser.Tokens是在词法分析阶段使用的。词法分析的任务是把源代码拆分成单个的“词”或“标记”。Token、NamedToken、StringToken、NumericToken,这些Tokens中的内部类就是用来表示这些标记的。词法分析器会使用Tokens来生成标记,然后语法分析器会使用这些标记和JCTree来构建完整的AST。
Tokens负责将源代码分解为更易于处理的小单元(Token),而JCTree则负责将这些小单元组装成结构化的抽象语法树,以便后续进行语义分析、优化和代码生成等操作。
Token
在编译器的词法分析阶段,源代码被分解成一系列的标记(token)。这些标记代表了Java程序语言中最小的词法单元,如关键字(if、for、switch、do等)、标识符、字面量(数字、字符串)、运算符(+、-、*、/)、界定符(括号、分号等)等。在 com.sun.tools.javac.parser.Tokens 中,定义了多个内部类来表示各种类型的标记:
-
Token:这是所有标记类型的基类。它包含了标记的类型(关键字、标识符、字面量等)以及在源代码中的位置信息 -
NamedToken:这个类用于表示标识符。一个标识符可以是一个变量名、类名、方法名等等。除了基本的标记信息,还存储了标识符的名称 -
StringToken:这个类用于表示字符串字面量。除了基本的标记信息,它还存储了字符串的内容 -
NumericToken:这个类用于表示数字字面量。除了基本的标记信息,它还存储了数字的值
这些标记类提供了对源代码进行分析和解析的基础。在这一阶段之后,编译器将这些标记传递给解析器,解析器根据Java的语法规则将这些标记组织成AST,然后进行语义分析、优化和代码生成等后续步骤。
TokenKind
TokenKind是Tokens下的一个内部枚举类,用来表示Java语言中的各种不同的标记类型。每种标记类型都对应一种特定的语法元素,例如IF对应if关键字,PLUS对应+运算符,IDENTIFIER对应变量名等。枚举值中还包括了一些特殊的标记,例如EOF表示输入的结束。
每个Token对象包含了一种TokenKind枚举值,表示此标记的类型,以及其他一些信息,例如标记在源代码中的位置、对应的源代码文本等。
public enum TokenKind implements Formattable, Predicate<TokenKind> {
EOF(),
ERROR(),
// other tokens
TRY("try"),
VOID("void", Tag.NAMED),
// other tokens
AMP("&"),
// other tokens
CUSTOM;
// constructors, variables and methods ...
}
PS:这里出现了一个非常显眼的CUSTOM枚举值,在CompletenessAnalyzer.TK中被引用CUSTOM(TokenKind.CUSTOM, XERRO) // No uses根据官方的注释这个关键字是未实现的而不是自定义的意思。
JavacParser
在com.sun.tools.javac.parser包中定义了DocCommentParser、JavacParser、JavadocTokenizer、LazyDocCommentTable、Lexer、Parser、ParserFactory、ReferenceParser、Scanner、ScannerFactory、TextBlockSupport、Tokens、UnicodeReader这13个与Java语法和词法解析相关的类。它们的大致的调用关系时序图如下(时序图比较大读者可能需要放大页面来查看):
大部分的类通过类名即可知晓作用,其中JavacParser最为重要,它和Parser类一起进行语法分析,使用由 Lexer 生成的词法单元来构建AST。绝大多数的关键字的处理流程也在JavacParser中被构建,因此要实现自定义关键字也必须在JavacParser中进行构建。在JavacParser的parseSimpleStatement核心方法中实现了简单Java语句的解析,这些简单语句包括:
-
声明语句:变量声明,类声明,方法声明等
-
表达式语句:方法调用,赋值操作等
-
控制流语句:if,for,while,switch,try/catch,return,throw等
-
块语句:由花括号
{}包围的一组语句
parseSimpleStatement 方法将读取并解析这些类型的语句,并将其转换为AST的一部分,以便进一步的编译阶段进行处理。但是该方法处理只一些比较简单、基础的Java语句,对于复杂的表达式或语句,例如嵌套的表达式或语句,可能需要通过其他方法进行解析。这个方法一般不会直接被外部调用,而是在 JavacParser 类的其他解析方法中被调用,以完成对整个Java源代码的解析。以try-with-resources/catch/finally为例进行片段分析:
case TRY: {
nextToken(); // 将pos移动到下一个token,可能是小括号也可能是花括号
List<JCTree> resources = List.nil();
if (token.kind == LPAREN) { // 如果是小括号则处理为try-with-resource
nextToken(); // 将pos移动到下一个token,花括号,也就是try的代码块
resources = resources(); // 解析resources
accept(RPAREN);
}
JCBlock body = block(); // 获取try的{}代码块并存入JCBlock对象
ListBuffer<JCCatch> catchers = new ListBuffer<>(); // 需要catch的异常的列表
JCBlock finalizer = null; // 可能存在的finally代码块
// 处理`catch`和`finally`
if (token.kind == CATCH || token.kind == FINALLY) {
// 将所有的catch异常循环放入列表中
while (token.kind == CATCH) catchers.append(catchClause());
if (token.kind == FINALLY) { // 再解决可能会存在的finally代码块
nextToken(); // 将pos移动到finally后的token,花括号
finalizer = block(); // 获取finally的{}代码块并存入JCBlock对象
}
} else {
// 这里处理只有try-resource且resource为空的异常
if (resources.isEmpty()) {
// 将发生异常的位置pos和异常类型抛给编译器处理
log.error(DiagnosticFlag.SYNTAX, pos, Errors.TryWithoutCatchFinallyOrResourceDecls);
}
}
// 将resource、try代码块、catch列表、finally代码块委派给TreeMaker进行AST的构建
return F.at(pos).Try(resources, body, catchers.toList(), finalizer);
}
在这段代码中实现了对try-with-resource的AST树构建,同时也涉及了pos变量的作用从而验证了之前对pos变量的结论和总结。在JavacParser类中不止有这个处理简单、基础的Java语句的功能,还包括了blockStatement()、localVariableDeclarations()等许多方法。
关键字的实现
在了解过Tokens.TokenKind和JavacParser.parseSimpleStatement后,似乎就可以尝试在JDK中实现自定义关键字的功能了。在本文中我将以添加retrial自定义关键字为例展开介绍,首先retrial关键字具备如下的功能:
-
这个关键字的使用格式为
retrial () () {}-
()第一个括号中传入一个布尔表达式,记作类型为JCExpression的condition变量 -
()第二个括号中传入一个int类型的变量或数值,记作类型为JCVariableDecl的loopCounter变量 -
{}花括号中需要传入一个代码块,记作类型为JCStatement的whileLoop变量
-
-
retrial在满足condition条件的情况下(condition==true)会对whileLoop代码块执行loopCounter次直到不满足condition条件或执行次数超过loopCounter
retrial的功能其实就是实现一种条件次数重试,它的作用其实是与for (int i = 0; i < loopCounter && condition; i++)是一致的。现在,按如下的步骤将这个关键字添加到JDK中(为了能在多平台上通过编译我更推荐使用英文注释而非中文注释):
-
进入
Tokens.TokenKind在枚举值中加入RETRIALpublic enum TokenKind implements Formattable, Predicate<TokenKind> { EOF(), // other tokens RETRIAL("retrial"), // add retrial keyword // other tokens CUSTOM; // constructors, variables and methods ... } -
在JavacParser的
blockStatement方法中将RETRIAL与其他同类型的关键字一同注入到简单Java语句解析方法parseSimpleStatement中@SuppressWarnings("fallthrough") List<JCStatement> blockStatement() { // other code switch (token.kind) { // other code // resolve assert, retrial, for, if and other simple keywords case CONTINUE: case SEMI: case ELSE: case FINALLY: case CATCH: case ASSERT: case RETRIAL: return List.of(parseSimpleStatement()); // other code } // other code } -
在JavacParser的
parseSimpleStatement方法的switch/case中增加retrial关键字的语法树构造逻辑(读者在尝试时请去掉中文注释,避免编译失败)case RETRIAL: { nextToken(); // 向下移动pos accept(LPAREN); // 解析第一个()中的条件语句 JCExpression condition = parseExpression(); accept(RPAREN); accept(LPAREN); // 解析第二个()中的整型变量或数值 JCExpression timesExpr = parseExpression(); accept(RPAREN); JCBlock body = block(); // 创建Name类型的循环次数变量loopCounterName Name loopCounterName = names.fromString("$retrial_counter"); JCVariableDecl loopCounter = F.VarDef(F.Modifiers(0), loopCounterName, F.TypeIdent(TypeTag.INT), F.Literal(0)); // 包裹整个循环条件: condition && $retrial_counter < times JCExpression loopCondition = F.Binary(JCTree.Tag.AND, condition, F.Binary(JCTree.Tag.LT, F.Ident(loopCounterName), timesExpr)); // 创建$retrial_counter++事件(语句) JCExpressionStatement incrementCounter = F.Exec(F.Unary(JCTree.Tag.POSTINC, F.Ident(loopCounterName))); // 将loopCondition和$retrial_counter++事件组装为while循环语句(也可以换成条件for循环) JCStatement whileLoop = F.at(pos).WhileLoop(loopCondition, F.Block(0, List.of(body, incrementCounter))); // 将loopCounter和whileLoop封装为JCBlock来构建AST return F.at(pos).Block(0, List.of(loopCounter, whileLoop)); } -
按照上面的步骤定义成功后参照《JDK源码编译与版号控制》步骤进行差量编译
make clean all或make clean images。 -
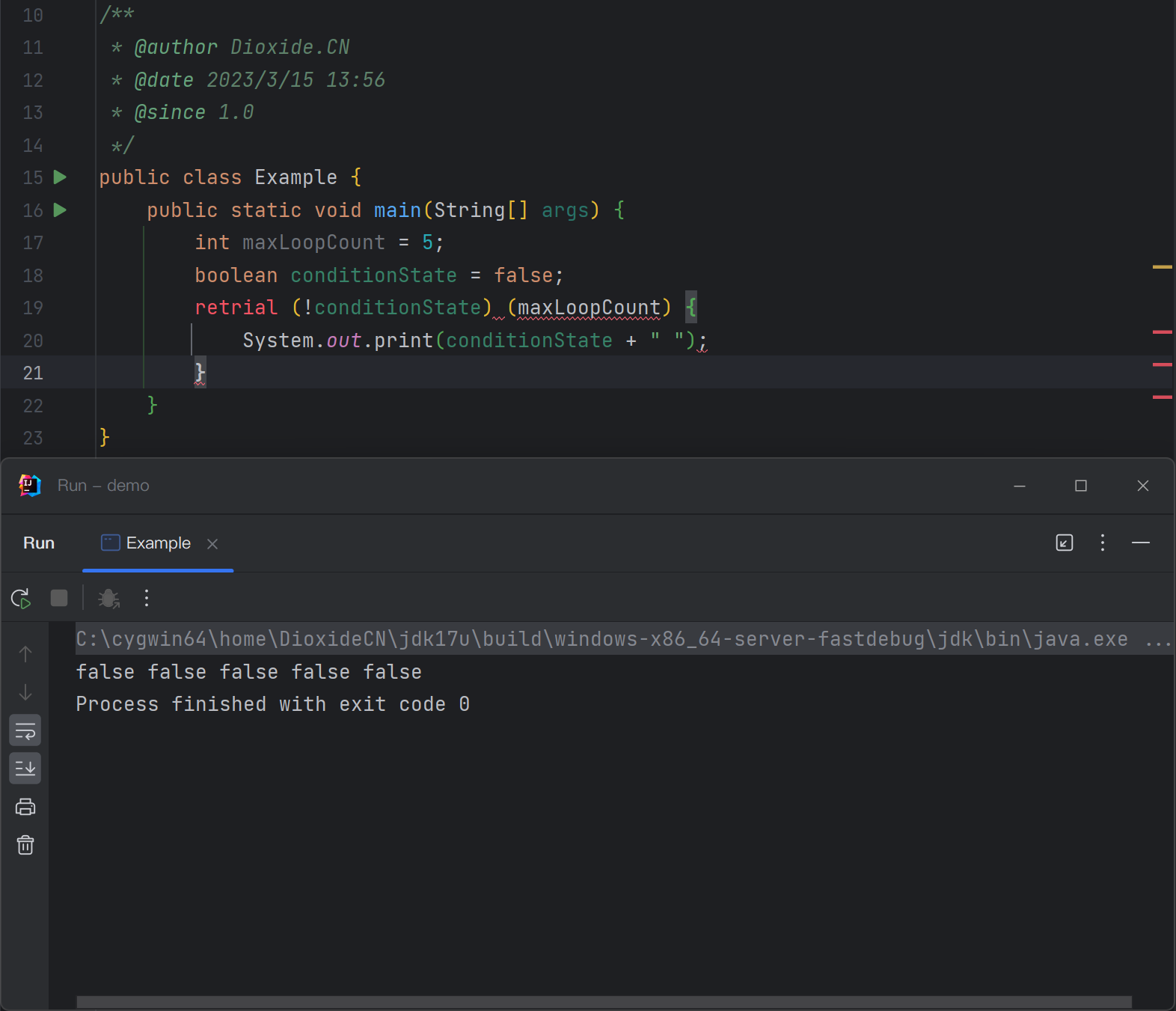
在IDEA中使用编译完成后这个JDK进行可行性测试。在IDEA中新建项目与
psvm入口,并写入以下测试代码:public class Example { public static void main(String[] args) { int maxLoopCount = 5; boolean conditionState = false; retrial (!conditionState) (maxLoopCount) { System.out.print(conditionState + " "); } } }最终的执行结果一定是5个false,因为条件conditionState没有发生过修改(爆红的原因是因为IDEA并不认得这个新添加的关键字,若想要不让它爆红则需要额外开发IDEA插件来支持这个JDK的retrial语法,读者可以自行尝试开发这里就不再赘述):
-
至此一个拥有自定义关键字的JDK就开发完成了,如果读者不想花费额外的时间来编译这个JDK,我也提供了一份已经编译完成的macOS版本和windows版本的JDK。读者可以通过下方Github的链接中进行下载尝试:
Release Haldir JDK 17.0.7+1 Release · Mordor171/Haldir-JDK (github.com)
参考文献
[1] Oracle. (2021). The Java® Virtual Machine Specification Java SE 17 Edition. Oracle Corporation. Retrieved May 16, 2023, from https://docs.oracle.com/javase/specs/jvms/se17/html/index.html
[2] OpenJDK. (2019). Building the JDK. Retrieved May 16, 2023, from https://github.com/openjdk/jdk17u/blob/master/doc/building.md
[3] Lindholm, T., Yellin, F., Bracha, G., & Buckley, A. (2015). The Java Virtual Machine Specification, Java SE 8 Edition (爱飞翔 & 周志明, Trans.). 机械工业出版社. (Original work published 2015)
[4] rajendarnalimela123. (2019). Java Tokens - GeeksforGeeks. Retrieved May 18, 2023, from https://www.geeksforgeeks.org/java-tokens/
[5] 纯净天空. (2008-2022). Java TokenKind类代码示例. Retrieved May 18, 2023, from https://vimsky.com/examples/detail/java-class-com.sun.tools.javac.parser.Tokens.TokenKind.html